
本次与大家聊一聊技术运营的“道法术器”,也是多年运维工作经验的沉淀和思考,期待与大家的交流与探讨,共同进步与提高。
运维的“道法术器”
首先什么是运维的“道”?—即运维的理念与价值观,我认为运维的“道”是聚焦于业务连续性的技术运营。
这里请大家思考,一旦我们管理的应用系统出现宕机,是不是之前的工作都白干了?很多人觉得不甘心。但规则确实如此,所以业务连续性是非常重要的。
“法”一般围绕质量、成本、效率与安全来做端到端建设。“术”就是具体的战术和手段,最后“器”就是工具体系。
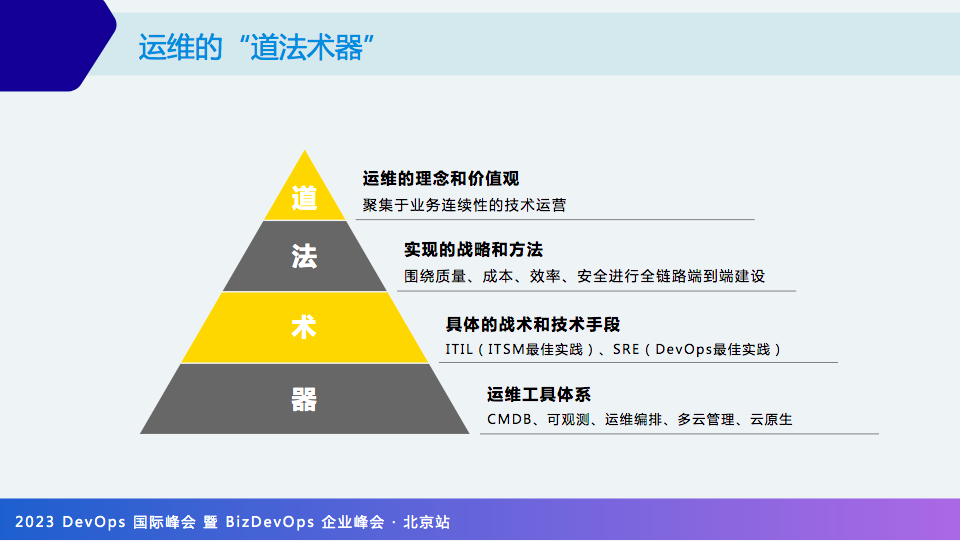
下面会围绕“法术器”来展开介绍,限于篇幅,“道”不在这里展开。
1
法:技术运营视角
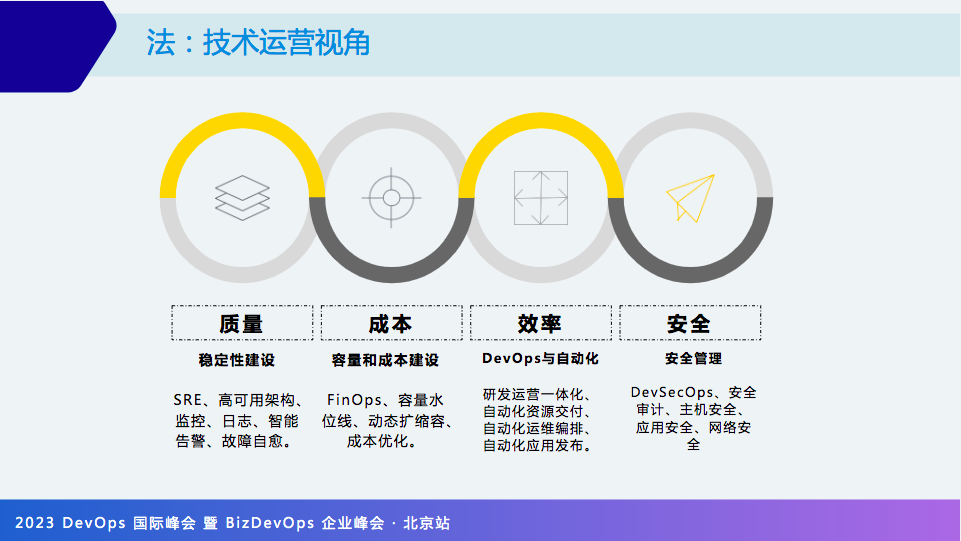
首先从技术运营视角来看“法”,主要是围绕质量、成本、效率与安全来做建设:
比如SRE、高可用、监控、日志等都属于质量范畴。
最近比流行的FinOps、动态扩缩容等都属于成本范畴。
所有运维自动化工具、DevOps 都属于效率的建设。
安全审计、DevSecOps、应用和网络都属于安全的建设。
2
法:应用视角

3
法:运维对象视角
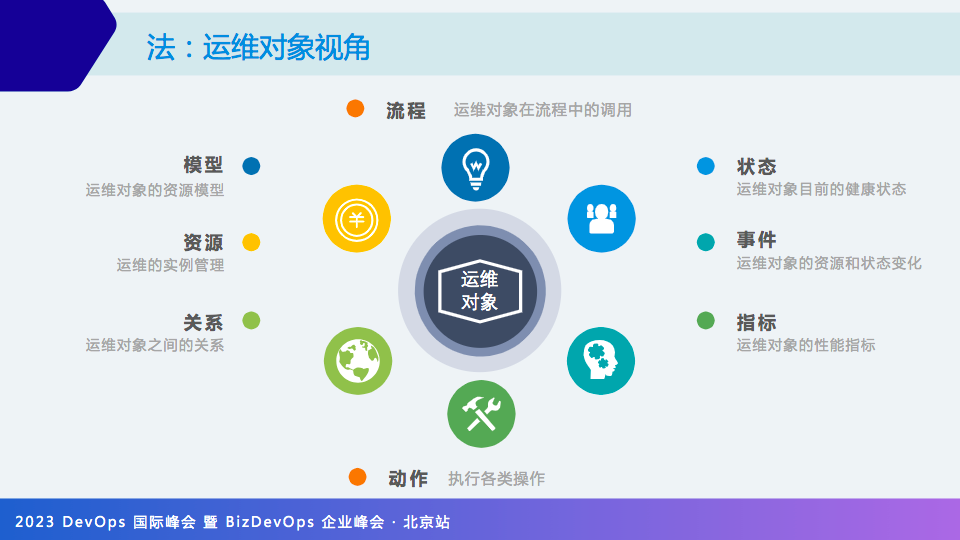
从运维对象视角,运维的“法”从8个角度来解释。
(1)模型:运维对象的模型,以数据库来举例就是要管理的字段。
(2)资源:资源就是运维对象有哪些实例。
(3)关系:运维对象之间的关系,例如 MySQL 与主机之间的关系。
(4)动作:比如数据库有创建数据库、用户、备份,这些都属于动作。
(5)指标:即运维对象需要监控的指标。
(6)事件:事件是指运维对象状态发生的变化, 通过捕捉这种转态变化,进行一些场景编排,例如故障自愈。
(7)状态:运维对象目前的健康状态,如果一个服务没有任何告警,健康度不一定是100%。我们会给每个运维对象健康度打分,通过巡检+监控得出分值。
(8)流程:运维对象在流程中的调用。比如服务工单,自动化运维的很多场景都需要调用运维对象。
术:SRE和XOps
运维的“术”其实有很多,这里从ITIL、SRE、FinOps 等角度来帮助大家理解。
1
术:DevOps技术运营标准
运维实践可以参考的标准有很多,中国信通院《研发运营一体化(DevOps)能力成熟度模型》的技术运营标准就是可参考的标准之一。
2
术:SRE可靠性工程
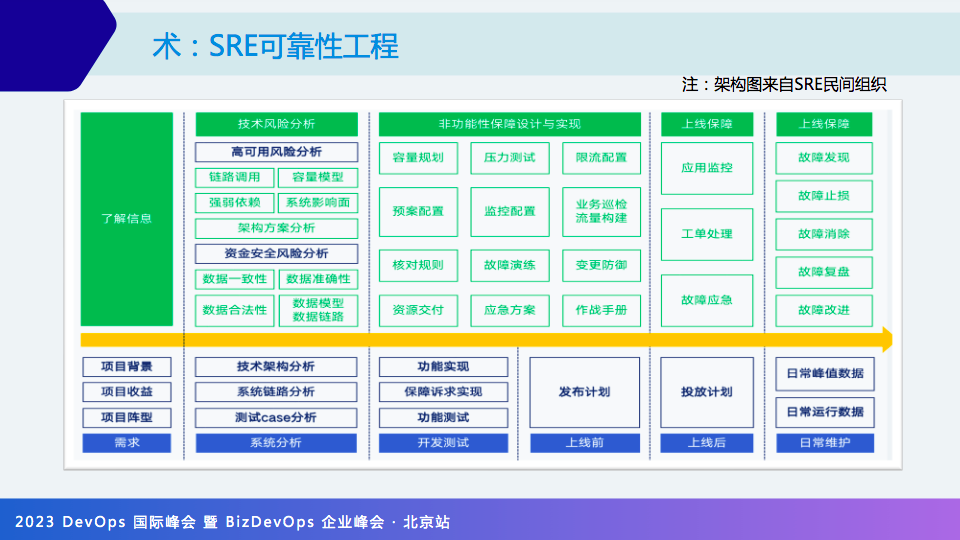
另一个可参考的是 SRE稳定性规范,上图来自SRE民间组织。
SRE可靠性工程要求在项目需求阶段了解项目信息;在开发建设阶段,主要是做系统分析、高可用风险分析和容量模型及链路可观测等内容,上线之后是压力测试、限流配置等。
这里分享一个最佳实践,我们要求运维团队针对每个应用系统都编写运维手册,手册里要求覆盖:应用背景、开发/部署架构、应急预案、常见问题、故障处理等,这样即使该应用的运维负责人离开的情况下,新来的负责人只需要翻手册就知道该怎么进行运维。
3
术:FinOps
现在互联网公司都在谈降本增效,目前比较火的FinOps,理念是帮助工程/财务、技术/业务团队在支出决策上进行协作,如何进行容量和成本管理,使组织能够获得最大的业务价值。
4
术:GitOps
细分领域里还有 GitOps,理念是将代码和配置都放入 Git 版本库中,通过 CI/CD 流水线进行运维管理。我曾接触一家外企,所有主机都通过 Terraform 进行管理,包括创建一个安全组规则,也是 Terraform 加一行代码,再通过 CI/CD 的流程提交 git,测试并上线。
5
术:持续运营
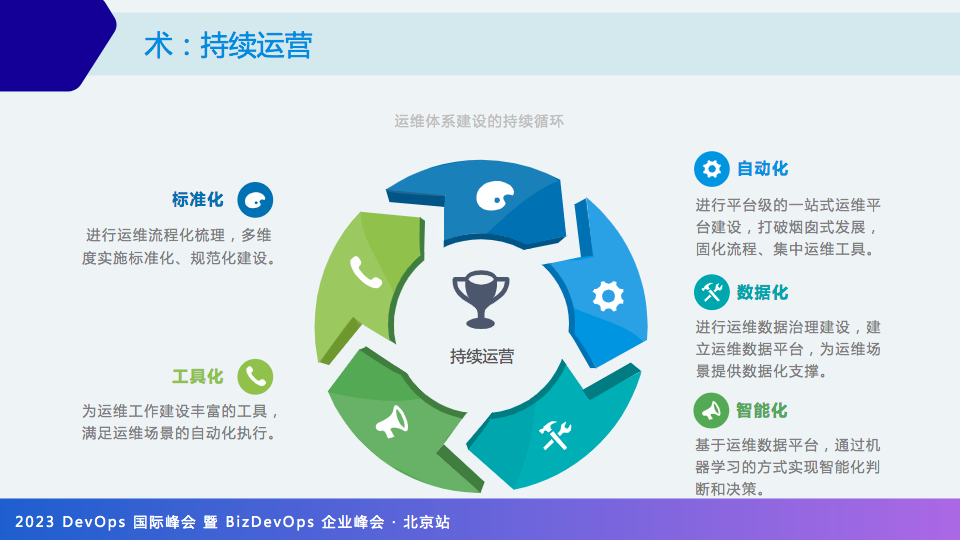
最后是持续运营。从标准化->工具化->自动化->数据化->智能化。
很多同学分不清工具化和自动化的区别在哪里。这里分享一个我个人的理解。
比如企业有了可观测、AIOps、日志等就是自动化了?并不是,只有将上述工具能力进行贯穿打通,才实现了真正的自动化。如果工具之间没有打通,即使建设的项目名称叫自动化运维,其实建设出来的依然只是一个工具。
第二是数据化,通往智能化的过程中,数据治理的作用必不可少,不讲数据治理的 AIOps 就是耍流氓,只有算法肯定不行,需要相应的运维大数据进行学习和训练才有可能进行智能化决策。

器:运维工具和平台
最后谈一下“器”,我做运维平台建设好些年,基本上是身心疲惫,分享一个感悟,很多东西不单靠产品能够解决,产品既不能让你自动化,也不能带来 AIOps。产品仅仅是帮助用户,甚至说引导用户来进行自动化建设,但是只依靠产品,并不是一个好主意。
1
运维工具平台的底层设计逻辑
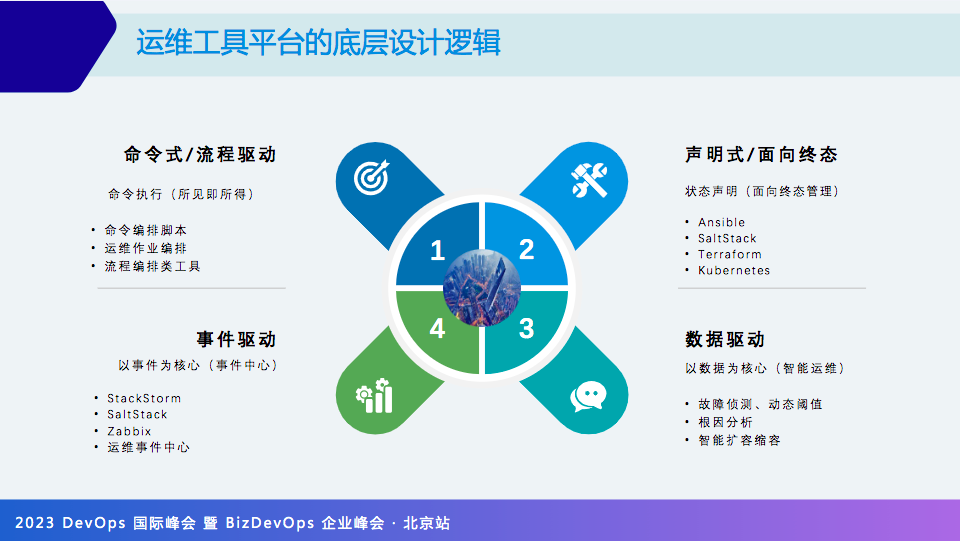
既然不讲产品,这里分享一下运维工具平台的底层逻辑,从设计角度来看,大部分工具平台都有以下逻辑。
-
命令式/流程驱动:所有的运维作业编排类都是命令式/流程驱动的,这也是最容易理解的逻辑。
-
声明式/面向终态:比如 Kubernetes、Ansible 等都是声明式的,面向最终状态的管理。
-
数据驱动:AIOps 很多来自数据驱动逻辑,运维大数据+机器学习算法,通过数据驱动实现智能化运维。
-
事件驱动:以故障自愈举例,当某服务宕掉被捕捉并发送到事件中心,事件中心做规则判断并执行一个工作流程,工作流尝试重启,健康检查成功后再发送自愈成功的通知。
如果失败就发告警通知,请人工处理,这就是以事件驱动的例子。
2
运维工具平台的底层管理逻辑
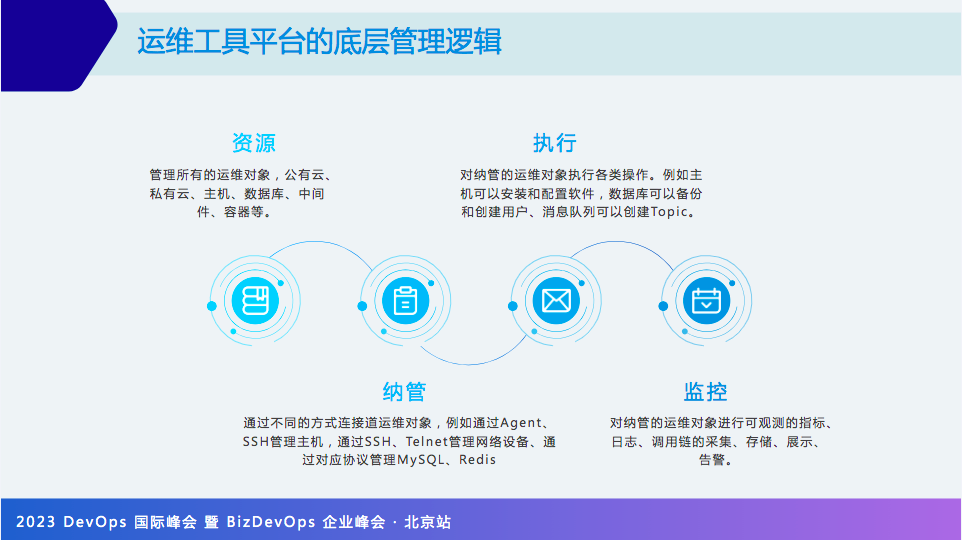
如果从运维管理管理逻辑来看,大部分工具平台也有以下四个逻辑。
-
资源:管理所有运维对象,像 CMDB、云管平台、容器平台都可以被理解为资源。
-
纳管:对不同运维对象进行纳管,有了纳管,我们才能对它进行下一步的操作。
-
执行:对纳管的对象进行操作,例如安装配置软件、备份、创建用户等操作。
-
监控:对运维对象进行可观测的指标、日志等进行采集、存储、展示等。
下面分几个方面来说。
3
资源管理:CMDB
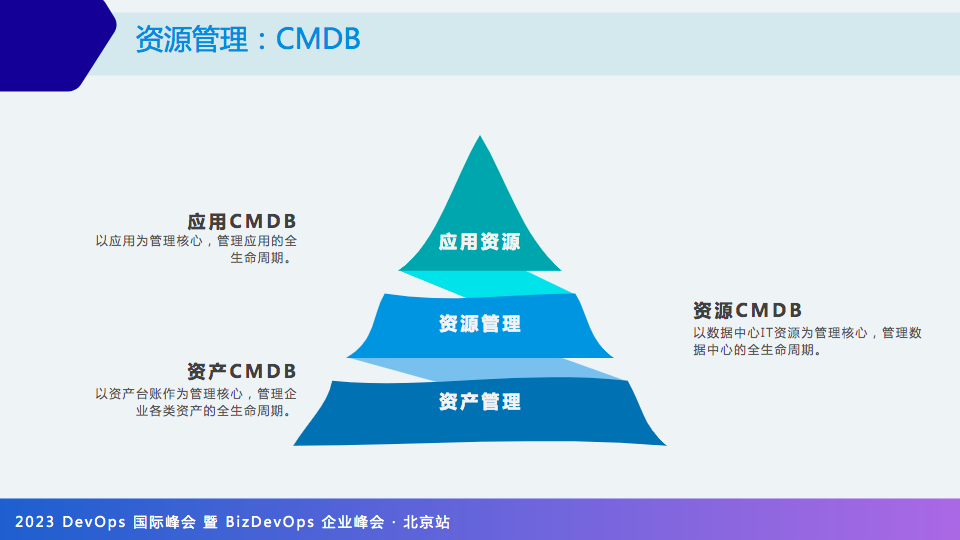
CMDB分享过很多,这里再简单介绍几个点。
CMDB 现在流行分层,分为资产CMDB、资源 CMDB 和应用的 CMDB。
CMDB 真正的作用在于数据消费,即使将数据全存得好好地,但消费场景与 CMDB 并未对接上,你的 CMDB 也就失去了意义。
举个例子,监控的主机来自哪里?如果不来自 CMDB,那可能走错了方向;自动化作业执行数据来自哪里?巡检的主机来自哪里?答案都是 CMDB。
见过了很多 CMDB 建设的例子,花费大量资金,建设也很完善,使用上都因为缺乏相关的场景,最后不了了之,这一点需要注意。
4
资源纳管:Agent/SSH/应用协议
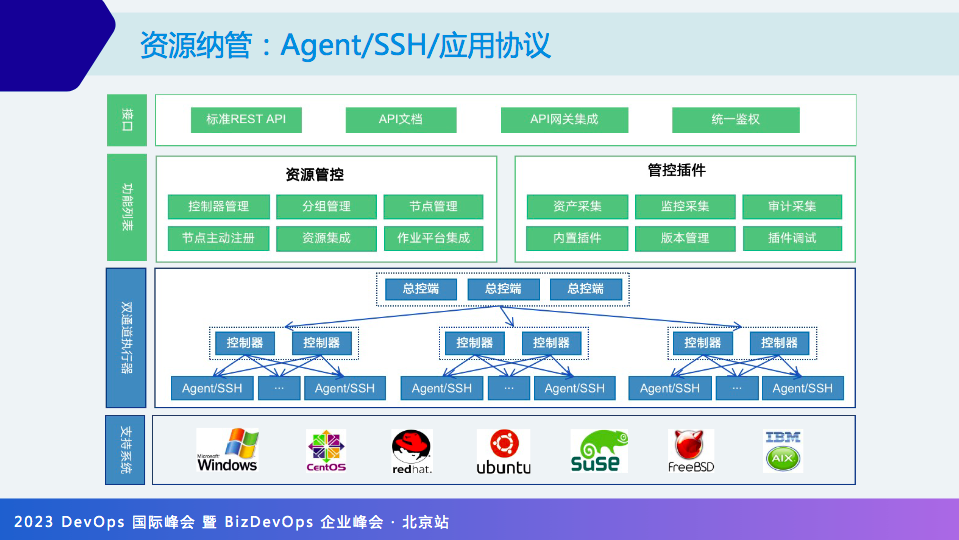
有了资源以后,下一步要建设的就是对资源对象进行纳管。
这里介绍 proxy,有点类似于传统的 master/proxy/agent,为了方便横向扩展,最后上面有个总控端,对外提供 API。
这里提一下 One Agent,个人觉得对此不要太迷信。因为不同的 agent 逻辑不一样,比如监控 agent 是隔多少秒做数据采集然后发出去,安全的 agent 的设计逻辑和执行都是不一样的。
4
以“资源”为中心和以“应用”为中心
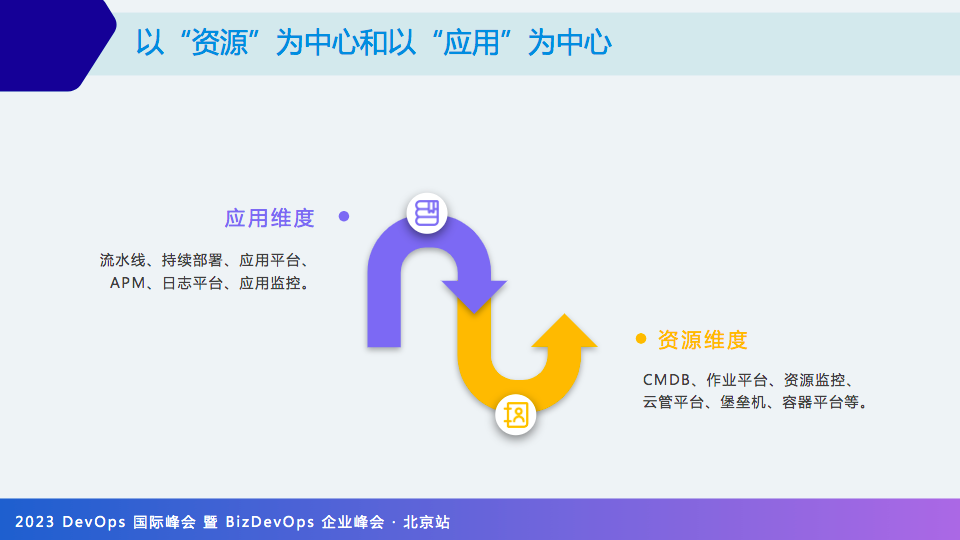
最后一个收尾,我们在自建或采购运维工具时,你要考虑两个维度,一是应用的维度,另一个是资源的维度,应用是资源的消费方,资源提供应用进行消费,比如CI/CD流水线、部署等都属于应用维度,这是对此进行一个总结。
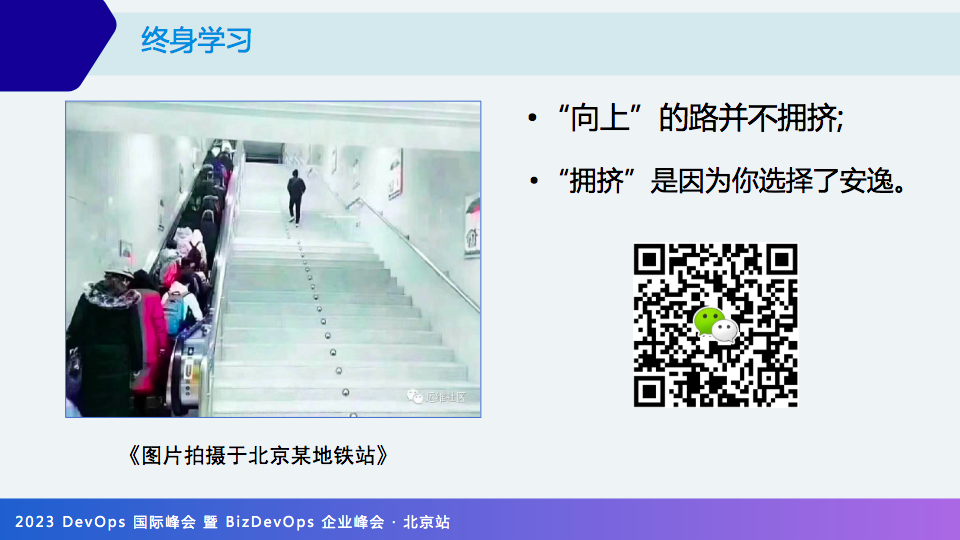
最后分享一个图片,图片来自于北京深夜的地铁站,在很多人都在排队坐滑梯的时候,有一个小哥背上电脑包,手插着口袋,悠闲的走了上去。
“向上的路并不拥挤”,“拥挤”是因为你选择了安逸。你想毫不费劲地走上去,就面临“拥挤”,因为这是很多人都想这条更容易的路。
这也告诉我们做 IT 运维技术的工程师,我认为是需要终身学习,如果有一天放弃了学习,你基本上就会停止不前。乾坤未定,你我皆是黑马,加油,运维的朋友们!
作者简介

赵舜东(班长)
高效运维社区核心成员
GOPS大会金牌讲师
本文根据演讲者在 DevOps 国际峰会 2023 · 北京站演讲整理而成,如有图文不妥,请以视频为准。更多精彩,请关注高效运维公众号。
End
近期好文:
什么是 Vlan、三层交换机、网关与DNS?这样理解省时又省力…
“高效运维”公众号诚邀广大技术人员投稿
投稿邮箱:jiachen@greatops.net,或添加联系人微信:greatops1118。